
Fontimize: Subset Fonts to Exactly and Only Your Website's Used Characters
Examples
Before the why, a quick preview of what: What is font subsetting? Creating new font files that can only render specific characters. Fonts are built to generically render any text, but that makes them big. If you change them so they can only render your text, you can make them a lot smaller. Embedding subsetted fonts in a website, built specifically to be able to render the text in that website and only that text, saves a lot of download file size and time. Readers never notice a visual difference because the subset is built to match what it’s rendering, your site, but your bandwidth and page load speed are greatly improved.
all_html_files = [ 'input/one.html', 'input/two.html' ]
font_results = fontimize.optimise_fonts_for_files(all_html_files) # Magic!
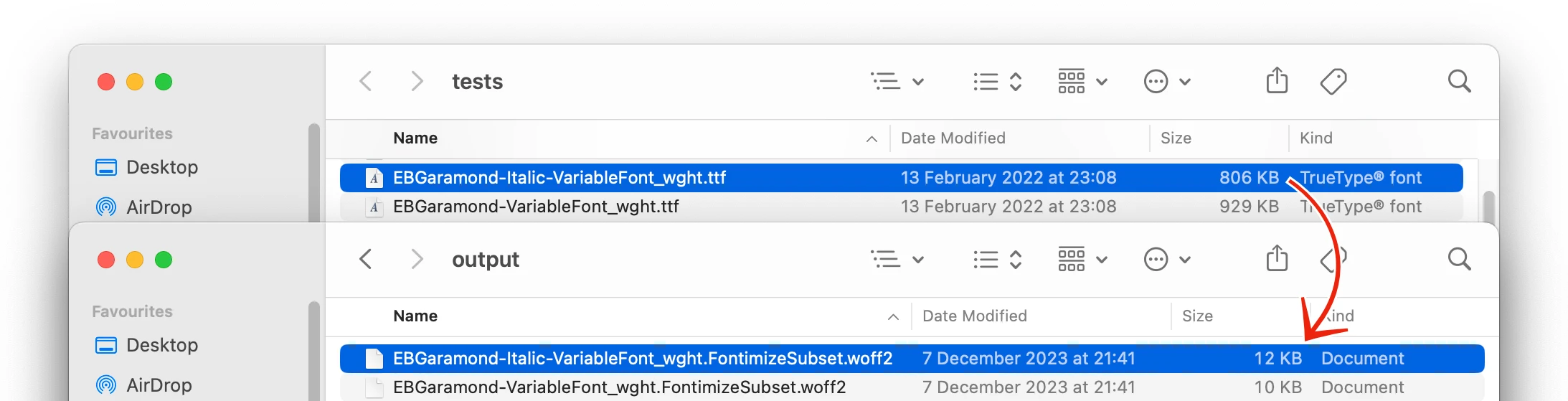
This magic method generates new versions of your fonts with all and only the glyphs needed to render this specific website. This library is used to build this website. You’re looking at the results right now. The new fonts are as small in file size as possible. Small, but the fonts contain every glyph needed. It even finds characters specified in CSS pseudoelements. Pass it a list of HTML files and it’ll do the rest.
Or the command line, here not processing files but a specific string:
$ python3 fontimize.py --text "ABCZabcz?" --o "cmdout" --fonts tests/SortsMillGoudy-Regular.ttf --subsetname "MinimalExample" --verbose
...
Generated the following fonts from the originals:
tests/SortsMillGoudy-Regular.ttf ->
cmdout/SortsMillGoudy-Regular.MinimalExample.woff2
Results:
Fonts processed: 1
Total original font size: 115KB
Total optimised font size: 2KB
Savings: 113KB less, which is 98.6%!
Thankyou for using Fontimize!
The generated font, SortsMillGoudy-Regular.MinimalExample.woff2, contains only the glyphs required to render text containing characters ‘ABCZabcz’ and ‘?’ .
In practice, for Dave on Design, the resulting font files are about 5-6% the size of the original, ie measured in low kilobytes rather than megabytes.
The API and command-line utility are flexible, allowing you to customise the output location, use specific font files, change verbosity, return information about what characters were found, what fonts were generated, and more.
Why? Megabytes Of Fonts :(
This site has an ethos of tech minimalism: it is pure HTML and CSS, no Javascript at all. A side goal is a fast website with small download size. And I had a problem. If you want, skip the story, get to the code.
For a typical article, the HTML is 7KB, CSS is 45KB, and header image is 85KB: that’s under 150KB total for the page. Not super-minimized, but for 2023 standards it’s decent.
But the fonts for the same page were 1.5 megabytes. This meant that:


- The site ‘looked bad’ the very first time you saw it—the browser couldn’t use the fonts it was designed for, so used fallback system-installed fonts: not ideal for a ‘design’ website, first impressions matter
- The initial load of the site took a noticeable amount of time: on several completely normal net connections, ten seconds or more
- A page would, at some point, re-render and re-layout as each font arrived. This looked janky.
Ideally the site would download fast, and look correct straight away. If you’re reading this, likely you want this for your site too.
Fonts used by Dave on Design See font credits. include EB Garamond for normal text, Cormorant Garamond for the italic form, Sorts Mill Goudy for headings, and Spirax for dropcaps. Of these by far the largest was EB Garamond at 929KB. The fonts by themselves are reasonable: the site has its own visual design to which the typefaces are key. Getting rid of them in favour of other fonts I work as a product manager, and my most recent knowledge in the area was of web-safe fonts (a tad outdated) and a vague idea that Google provided fast font servers with GDPR problems, noting that this site serves its own fonts—it uses no cookies or other privacy tracking at all. I wasn’t even aware there was a web font format, I thought everyone used TTF or OTF. Hah! was not an option. However, I had read of a fairly new (pre-Covid?) web optimization trend called font subsetting, where font files are generated that contained only a subset of everything normally inside a font: all Latin characters omitting all Cyrillic or Greek, for example. The idea is to make a font considerably smaller while still allowing it to render a page.
An ideal pipeline for a Python static site generator is to generate the site, and, during this, pipe the site to a magic library that uses it to generate the new fonts.
A Magic Library. Yes.
I’m a big believer in code that does the right thing by default. I don’t want to have to figure out what characters are used on my site, far less parse CSS and find the pseudo-elements that add text (ie characters) that are rendered onscreen. Instead, I do want a pipeline that takes input and generates the correct output. That input is the entire site: feed it the HTML files, it follows CSS links, loads the CSS, parses that for referenced font files My static site generator already knows these, but this lets you run on arbitrary set of HTML. plus CSS that causes character rendering, and uses those.
And it shouldn’t subset just for glyph categories like Latin: if we’re doing this, do it right: it analyses exactly which characters are used and the resulting font files are a genuine subset, as small as possible, targeted only for that specific site’s text at the time it was generated.
Some Googling showed a Python library that could convert fonts, and create subsets if you specified the input Unicode glyphs, but you’d have to write wrapper code to use it. There was no drop-in Python library that magically just worked: took HTML+CSS, analysed, and generated fonts.
So I wrote one.
This is the third major piece of Python code I’ve written, and first to publicly share.
Introducing Fontimize
Fontimize is both a Python library, and a command-line app if that suits your pipeline / usage. It takes as input: a set of HTML files on disk. It gives results:
- On disk, a set of new font files
- In code (or for verbose console output), a list of the CSS files it found, and a dict mapping old to new font filenames, for you to use to rewrite that CSS. Fontimizer doesn’t rewrite CSS: it aims to do one thing well, which is optimize and subset fonts. It gives you the data you need to rewrite CSS.
The new font files contain only the glyphs needed to render the input HTML and CSS, nothing more. If your input text does not use every character A-Z, then some of A-Z will be missing. If your input text uses a single Kanji character, then only that Kanji character (the glyph or glyphs required to render it) will be in the output font file, assuming they were in the input font file to start. This is not quite true. There are a few variations generated: if the input contains straight quotes or dashes, then curly quotes and en- and em-dashes will be included. But it is almost only the direct glyphs that are in the input. The point is, if something is definitely not required by the input it will not be in the output.
all_html_files = [ 'input/one.html', 'input/two.html' ]
font_results = fontimize.optimise_fonts_for_files(all_html_files)
print(font_results["css"])
# Prints CSS files found used by any of the HTML input files:
# { 'input/main.css',
# 'input/secondary.css' }
print(font_results["fonts"])
# Prints pairs mapping the old fonts to the new optimised font generated for each. Use this to, eg, rewrite your CSS
# By default exports to the same folder as the input files; use `font_output_dir` to change
# { 'fonts/Arial.ttf': 'fonts/Arial.FontimizeSubset.woff2',
# 'fonts/EB Garamond.ttf': 'fonts/EB Garamond.FontimizeSubset.woff2' }
print(font_results["chars"]
# Prints the set of characters that were found or synthesised that the output fonts will use
# { ',', 'u', '.', '@', 'n', 'a', '_', 'l', 'i', 'h', 'Q', 'y', 'w', 'T', 'q', 'j', ' ', 'p', 'm', 's', 'o', 't', 'c' ... }
print(font_results["uranges"]
# Prints the same set of characters, formatted as ranges of Unicode characters
# U+0020, U+002C, U+002E, U+0040, U+0051, U+0054, U+005F, U+0061-007A ...
Flexibility
Doing the right thing magically doesn’t mean doing something only one way with no options. You can have a tightly purposed, specific library, but have an API that is adaptable to how your users want to use it. Hopefully, I’ve hit this balance with Fontimize. There’s a Github issues page, and I’ll pay attention to what’s filed there.
The API is fully documented on Github, but a short summary of things you can do is:
- Convert arbitrary fonts—just pass in the filenames
- Use your own text to generate the required glyphs, either instead of or in addition to text found in input files
- Change the name used for the output font (the filename contains
FontimizeSubsetby default)—it’s important to differentiate input fonts from output fonts because by definition they are incomplete, but by all means call them whatever you want - Verbosity and statistic printing output can of course be changed
- There are different methods that let you parse HTML string(s), plain text, etc, as well as the general ‘throw a set of HTML files at it’ super-method
And if that’s all you need, you can stop reading here! Remember, python3 -m pip install fontimize and then use fontimize.optimise_fonts_for_files([list]); full documentation here. I hope you find it useful and it assists minimizing your website bandwidth.
But if you’d like to see some of its code, find out what a Python newbie like myself struggled with when writing it, etc, read on!
How does it work?
This is my first published Python library, so it’s a bit of an adventure making it public. Previous Python apps are the static site generator for this website, which was my first non-trivial Python app and I’m very aware has some poor code; and a template library that the SSG uses. I might make it public sometime: it’s pretty cool; it is a virtual template engine which calls back into code. This is used to allow me to write Python code that mutates and changes what is replaced in the template location.
The code is almost embarassingly simple and I’m very sure has some areas of improvement. I am also still learning how to make things Pythonic. If it helps, it does have fairly comprehensive unit tests. Let’s dig in to how it works, and some of the Python newbie-ish problems I had along the way.
Unique characters and glyphs
All methods like optimise_fonts_for_files() call the core method, optimise_fonts(). This takes a string which contains all the text that needs to be rendered; a list of font files; and config like the font output path and output subset name.
That text parameter is not a unique set of characters: it’s just the text as passed from the user, or a concatenated set of strings ripped from HTML.
The first step is to get a unique set of characters (ie a container which contains each unique character, once) from the text:
characters = get_used_characters_in_str(text)
where:
def get_used_characters_in_str(s : str) -> set[chr]:
# Always contain space, otherwise no font file generated by TTF2Web
res : set[chr] = { " " }
for c in s:
res.add(c)
return res
This returns only the characters that are actually used. I love languages that have data structures like sets and maps/dicts built in. My day job is C++, and the amount of things that are in the C++ library verges on ridiculous—std::func and std::bind anyone? Surely function binding is a language feature not a library feature! Python reminds me of Delphi, where one feature I used to love in the language was the set keyword which I often used, just as here, for characters. But that’s not enough: the website generator actually mutates the characters for both quote marks and dashes. For example, if there is an input single quote, that will be changed to a ‘curly quote’, direction depending on the text. This is handled kindof hackishly:
def get_used_characters_in_str(s : str) -> set[chr]:
# Always contain space, otherwise no font file generated by TTF2Web
res : set[chr] = { " " }
for c in s:
res.add(c)
# Check for some special characters and add extra variants
if res.intersection(set("\"")):
res.add('“')
res.add('”')
if res.intersection(set("\'")):
res.add('‘')
res.add('’')
if res.intersection(set("-")):
res.add('–') # en-dash
res.add('—') # em-dash
return res
There has to be a better way to do this: maybe ask the font for alternates for each character? The font library already automatically generates ligatures and other variants, but specifically does not for quotes. Consider this an area of improvement in future.
Character ranges
The TTF2Web library requires a set of Unicode ranges representing the characters. I created a charPair type to represent a pair of start & end characters, ie a range:
class charPair:
def __init__(self, first : chr, second : chr):
self.first = first
self.second = second
def __str__(self):
return "[" + self.first + "-" + self.second + "]" # Pairs are inclusive
# For print()-ing
def __repr__(self):
return self.__str__()
def __eq__(self, other):
if isinstance(other, charPair):
return self.first == other.first and self.second == other.second
return False
def get_range(self):
if self.first == self.second:
return _get_unicode_string(self.first)
else:
return _get_unicode_string(self.first) + '-' + _get_unicode_string(self.second, False) # Eg "U+0061-0071"
The key is get_range(), which returns the range in the format TTF2Web wants, U+nnnn-mmmm). There is no U+ for the second part of the range. This is generated by _get_unicode_string:
def _get_unicode_string(char : chr, withU : bool = True) -> str:
return ('U+' if withU else '') + hex(ord(char))[2:].upper().zfill(4) # eg U+1234
How do you get a list of these Unicode ranges from the set of unique characters? Convert the set to a list; sort it; then iterate while you find sequential values (50, 51, 52, etc); once there is a break (52, 53, 70—bang!) generate a pair representing the start and end of that sequence and start again at the point you found the break (first becomes, in this example, 70, and you continue through the sorted list). If you hit the end, ensure the ending sequence is added.
# Taking a sorted list of characters, find the sequential subsets and return
# pairs of the start and end of each sequential subset
def _get_char_ranges(chars : list[chr]) -> list[charPair]:
chars.sort()
if not chars:
return []
res : list[charPair] = []
first : chr = chars[0]
prev_seen : chr = first
for c in chars[1:]:
expected_next_char = chr(ord(prev_seen) + 1)
if c != expected_next_char:
# non-sequential, so time to start a new set
pair = charPair(first, prev_seen)
res.append(pair)
first = c
prev_seen = c
# add final set if it hasn't been added yet
if (not res) or (res[-1].second != prev_seen):
pair = charPair(first, prev_seen)
res.append(pair)
return res
I feel like this is a lot of code for a conceptually simple idea, which probably means there’s a more Pythonic way to do it. In the past, the solo-dev way to find this out would have been asking questions on Stack Overflow or Code Review Stack Exchange. These days Copilot makes what would have taken a day or two of turnaround a matter of minutes. Copilot told me it was ‘already quite Pythonic’ and ‘it’s clear, concise, and makes good use of Python’s built-in functions’ but suggested:
res = [charPair(first, prev_seen) for first, prev_seen in zip(chars, chars[1:]) if chr(ord(prev_seen) + 1) != first]
As a Python newbie I can tell this is more Pythonic because it uses the for-in-if construct I’ve seen before, but I find it very hard to grok. The conditional check is after the statement executed if it’s true. I mentally think ‘if condition then do-something else fallback’, but this is ‘do-something if condition else fallback.’ Maybe the idea is to put the expected or key path first? I have not (yet) rewritten the code in such a short form. I believe code is read more than it is written, and I can’t yet read the above single line as clearly as I can the multiple original lines.
Unicode ranges for unique characters for the generated font
From all this—getting input text, converting to a set of unique characters, adding variant characters, and sorting and converting to Unicode ranges—we can convert a string of essentially random text to a specification of Unicode character subset ranges suitable for the TTF2Web font library.
What about HTML?
Glad you asked: the above get_used_characters_in_str() expects a string of (random) text, which is ripped from HTML. How?
The answer is BeautifulSoup: a library so famous I’d heard of it even before I started using Python. If you haven’t, I’m glad to introduce you! It parses HTML. And following the same principle of being a magic library that lets you do what you actually want, getting the entire human-visible text from HTML is as simple as:
soup = BeautifulSoup(html, 'html.parser')
return soup.get_text()
That’s it. Pass in <span><a href="#">Hello</a> world</span>, and it will return “Hello world”. I do this passing the entire contents of each HTML file.
CSS pseudo-elements
A rendered website can contain text and characters that are not in the HTML. For example, this sidenote Hello. has an asterisk and that asterisk does not appear in the HTML for the sidenote. This is done in the CSS, which uses a :before pseudo-element to place an asterisk at the start of the sidenote.
BeautifulSoup also lets you find the externally referenced CSS files:
def _get_path(known_file_path : str, relative_path : str) -> str:
base_dir = path.dirname(known_file_path)
# Join the base directory with the relative path for a full path
return path.join(base_dir, relative_path)
# Extract CSS files the HTML references
for link in soup.find_all('link', href=True):
if 'css' in link['href']:
css_ref = link['href']
adjusted_css_path = _get_path(f, css_ref) # It'll be relative, so get full path relative to the HTML file
css_files.add(adjusted_css_path)
Using tinycss2, you can parse for :before and :after pseudo-elements, and extract the content. I found this quite laborious: there’s a lot of indented logic, and you have to serialise rules Why? It just parsed them, surely it has some kind of iterable data structure? and parse them manually. Alternative techniques (courtesy of Copilot, since Google returned nothing!) often caused tinycss2 to crash, and I don’t know if that’s user/AI error or library issues. I think I would prefer some other way of navigating CSS, such as querying for rules matching certain behaviours (effectively, ‘return a list of rules applying pseudo-elements’ and then for each rule, ‘find the content line and give me its value’.) I wonder if this is a common problem? Googling for Stack Overflow CSS solutions tends to show a lot of people using regexes or other parsing and avoiding CSS libraries. Is it that those answers are low quality but high in search results, or do people who know more than I do avoid the tinycss2 library, or am I just searching for the wrong thing?
def _extract_pseudo_elements_content(css_contents: str) -> list[str]:
parsed_css = tinycss2.parse_stylesheet(css_contents, skip_whitespace=True)
contents = []
for rule in parsed_css:
if rule.type == 'qualified-rule':
prelude = tinycss2.serialize(rule.prelude)
if ':before' in prelude or ':after' in prelude: # this is something like cite:before, for example
declarations = tinycss2.parse_declaration_list(rule.content)
for declaration in declarations:
if declaration.type == 'declaration' and declaration.lower_name == 'content':
content_value = ''.join(token.value for token in declaration.value if token.type == 'string')
contents.append(content_value)
return contents
# Extract the contents of all :before and :after CSS pseudo-elements; add these to the text
pseudo_elements = _extract_pseudo_elements_content(css)
for pe in pseudo_elements:
text += pe
However: ugly as this is, it gets a string that contains the user-visible text contents of all HTML files, and CSS pseudo-elements. It’s all the characters in this text that we need to be able to render in the generated fonts.
Finding font files
While the API does let you pass in a list of font files you want to optimise, Fontimize automatically finds all the ones your CSS references by default.
Again, this is ugly code. I can’t help feeling there is a better way to use tinycss2, but equally, whatever it is, I can’t find it, not even using Copilot! I feel like I expect an API to query for types of rules and find or query for their contents. Maybe I should write one! I’m still in the ‘other people must have experienced this, so either I am misunderstandng the library, or there really isn’t a need for a different API’ stage of thinking. Ie I need more understanding on my part before assuming there is a genuine lack here. However, yet more nested loops and ifs Using indentation as a proxy for code complexity, eight levels of indentation indicates ‘this can be done better’. give:
def _find_font_face_urls(css_contents : str) -> list[str]:
parsed_css = tinycss2.parse_stylesheet(css_contents)
urls = []
for rule in parsed_css:
if rule.type == 'at-rule' and rule.lower_at_keyword == 'font-face':
# Parse the @font-face rule, find all src declarations, parse them
font_face_rules = tinycss2.parse_declaration_list(rule.content)
for declaration in font_face_rules:
if declaration.type == 'declaration' and declaration.lower_name == 'src':
# Manually parse the declaration value to extract the URL
for token in declaration.value:
if token.type == 'function' and token.lower_name == 'url':
urls.append(token.arguments[0].value)
else:
continue;
# The `for token in declaration.value:` part is instead of:
# src_tokens = tinycss2.parse_component_value_list(declaration.value)
# which generates an error swapping U+0000 with another value. Unknown why.
Note this code avoid a tinycss2 crash: it manually parses the tokens in the src declaration, because the Copilot-suggested code parse_component_value_list() generated an error. I spent considerable time debugging this even checking the characters used in the CSS file. Eventually I reached the “must be user error but goodness knows what it is, just do it another way” stage of coding.
I feel really bad showing two such ugly pieces of code in this article.
Generating the font files
Fontimize started as a wrapper for TTF2Web. Using this to generate a WOFF2 font in a specific output (‘asset’) location, for a set of Unicode ranges, is very simple:
for font in fonts:
assetdir = fontpath if fontpath else path.dirname(font)
t2w = TTF2Web(font, uranges, assetdir=assetdir)
woff2_list = t2w.generateWoff2(verbosity=verbosity)
Fontimize has a ‘do not alter the input’ ethos, A good rule to follow for code safety—consider it a kind of defensive programming. If you use a library you want to know it won’t do something unexpected like, say, delete its input. and this is one reason it does not rewrite CSS but leaves the Fontimize API consumer to do so. The other reason is wrangling tinycss2—if you think I had trouble reading CSS, I don’t want to even try changing CSS using it. A lot of people online seem to use regular expressions for their CSS mangling, and, uh, I do too. And even if it’s okay for my own code I won’t do that in a publicly published library that has to work on unknown input. One exception is that when generating the output WOFF2 font files, there is neither a check nor warning if they already exist. They’re just overwritten. This is TTF2Web behaviour, and I’m considering changing the backend to the library that TTF2Web itself wraps, fonttools, specifically to add output overwrite checks.
And that’s it! It’s about 400 lines long, but that’s the core.
Other bits
Some random notes:
- Fontimize adds quote mark and dash alternates, but it looks like
TTF2Weborfonttoolsautomatically ensure ligatures and other font variations are present in the file. I’ve used FontDrop to test the font file contents, because macOS’s Preview and Font Book do not understand WOFF2 fonts. - Unit tests have been invaluable. The
tests.pyfile in the Fontimize repo is my largest use of Python unit testing to date. I found several bugs writing tests, and the process of writing tests was also valuable to make me think of use cases that had not been thought of when I started the library: for example, my website uses Latin characters, and after writing tests for various subsets I realised I needed to test other character sets and languages. This meant I added tests for Vietnamese, Kanji, and Devangari. - FontDrop also let me enter arbitrary text to ensure that, visually, the subsetted font rendered the same phrases visually identically as the original font, which was important for verifying languages and characters I do not understand.
- Type safety. As a relative newbie to Python, I found it incredibly flexible when first starting but pretty soon very fragile when refactoring anything remotely complex. Type hints are immensely helpful. Even if they were completely ignored by the tooling, they would still be useful to me. I am squarely on the side of type safety, but also really enjoying Python. I only wish the type hints were a bit more strictly enforced or linted by my Python tooling (VSCode with the Microsoft Python plugin.)
- Right now, Fontimize parses HTML (and CSS files used by the HTML files) and treats all other input files as text. It seems interesting to allow a user-defined callback to extract the text from any file: suppose you want to optimise fonts for your PDF files, or Markdown files, or… This is a really cool idea, but I know of no actual use case, because PDFs already optimise their embedded fonts, Markdown is transformed to HTML, and the only font optimisation need I know of is the web. So while it was tempting to expand the library, this falls into the ‘doing because it’s cool not because it’s useful’ area and I have not. You can file an issue if this would genuinely be useful for you!
- Fontimize generates the same glyph set for each font it generates. Dave on Design uses one font just for dropcaps, and so the used characters for dropcaps are likely significantly fewer than the use characters for the site as a whole. But the subsetted dropcap font contains the same glyph range. A possible future expansion would be to apply CSS to try to figure out exactly which characters are used for which font, not by text analysis but by style and element analysis. I suspect this would be a lot more error-prone (what if styles are changed at runtime?) and, since the subsetted fonts are already so much smaller than the originals, not a strong priority.
- Does using Fontimize count as changing or modifying the font? I am not a lawyer, so I don’t know. But the glyphs that are included are not knowingly modified, and it’s the glyph shapes that define a font. Plus, the font is clearly labeled as a subset; it is never represented as containing the full set of glyphs for the font face.
Python Packaging Tutorial: the Missing Bits
I also learned how to publish packages on Python’s PIP package manager. Missing bits of information I found useful are:
- It wasn’t clear to me that code samples like this went in the
pyproject.tomlfiles; I thought they’d be in a separate config file for your build system, ie (for me) a Hatch config file. - The tutorial license section implied the
LICENSEfile would be picked up automatically, but it didn’t seem to be (withpip show fontimizeafter installing.) I now have both a license classifier and a license file reference. - The default file selection did not find my
fontimizer.pyfile, because the tutorial names your project with your username suffixed, causing the default heuristics to fail. This seems a very basic ‘did anyone run through the tutorial?’ test. Maybe no-one else has actually run through it but just thought, ‘Eh, I don’t need no tutorial!’ Mypyproject.tomlnow includes the following, which includes my Python files, excludes some test folders, and specifies my specific Python file as the package (I think):
[tool.hatch.build.targets.sdist]
include = [
"*.py",
"LICENSE",
"readme.md",
"/images",
"/tests",
]
exclude = [
"/cmdout",
"/tests/output",
"/__pycache__"
]
[tool.hatch.build.targets.wheel]
packages = ["fontimize.py"]
- You have to manually specify dependencies: this means you have duplicated information between your Python files, which have the actual dependencies listed inside them as
importstatements, and the build config. The build system seems to have no dependency checking so if this gets out of sync you may not realise. In addition, the tutorial specifically recommends to not install dependencies (--no-deps) when installing your testpypi package. To quote, ‘It’s possible that attempting to install dependencies may fail or install something unexpected… it’s a good practice to avoid installing dependencies when using TestPyPI.’ —source. I personally prefer my test environments to mirror my real environments as much as possible, and if my project has dependencies, I want to at least check they’re nominally installed when installing—especially because I did not originally realise they were not automatically picked up by the package build system. - The full documentation for packaging has an example that includes these, even though they’re not obvious Not obvious to me. when reading through the tutorial.
- Also your dependencies should not include
osandsys, even if these are imported by your script. This is not obvious. (Yes, they’re inbuilt—but they’re used by the script so either should be specified or no harm specifying for completeness, right? No, there is harm, you will get:ERROR: Could not find a version that satisfies the requirement os (from fontimize) (from versions: none).) - When installing in production, ie PyPi, you will get errors: The
ERROR: Ignored the following versions that require a different python version: 3.10.0.0 Requires-Python >=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <3.5; 3.7.4.2 Requires-Python >=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <3.5
pyproject.tomlfile contains a clause,requires-python = ">=3.9". (I am using Python 3.11.) The only way I found to fix this error was to remove therequires-pythonclause completely. I wonder if there is apipbug here, and the version dependency is interpreted as three-point-one-one, not three-point-eleven? - If I’d tested packaging on something more closely resembling PyPi itself, not test.pypi, I would have found these issues. As it is, I moved from version 0.8.5 to 0.8.9 on the ‘production’ PyPi while fixing things that did not show on test.pypi following the tutorial. I yanked the older versions. This shows on the project releases page and IMO makes me look amateur—which I am, but still!
- How does a readme on PyPi specify an image? Currently my PyPi page uses the same readme as the Github repo , which references a screenshot in the
images/subfolder. This displays on Github but not on PyPi. Why? Does it not package everything? The folder is specifically included in the build script. When I look at the broken image link, it’s clearly been changed by PyPi itself because it’s no longer a simple relative URL: it’s on a weird domain:pypi-camo.freetls.fastly.net. But even though edited by PyPi (?) , it’s broken. Eh what?
Thanks!
As a spare-time project, Fontimize took 58 commits over the past three weeks, after being started from some hackish though already functional code in my site generator that I realised would be useful to refactor out. About half the commits affect tests, which reflects (to me) the value of working from tests back to code.
Dave on Design now takes about 6% of the bandwidth for fonts as it did before integrating Fontimize.
If you have any need to optimise your website loading time, I hope you find Fontimize useful!
Go shrink those fonts!